

My Journey to Breaking Into Data Science without a Masters or PhD
A Compilation of my "Breaking Into Data Science" series

👩🏻💻 Learn 🔄 Do 🔄 Teach 👩🏻🏫
My personal mandate: ⭐️ Develop ML platforms & MLOps systems that work, no matter the business or technology constraints; ⭐️ Contribute to the open-source MLOps ecosystem & continue to drive innovation; ⭐️ Create high-quality & thoughtful content that helps everyone in production ML become more productive, collaborative, & happier.
As an MLOp practitioner & educator I do this by:
✅ Hacking projects using best-of-breed tools & practices from software engineering, DevOps, data engineering, & machine learning using open-source & public cloud (GCP, AWS);
✅ Consulting with startups & enterprises (at all levels of Data & ML maturity) developing production ML pipeline, systems, & tooling;
✅ Writing books, videos, courses, & workshops to teach MLOps best practices & architectures;
✅ Growing communities & facilitating dialogue through my youtube, substack, twitter, & twitch platforms.
I've lead & executed key Data Science & MLOps initiatives at Mailchimp (Intuit), Teladoc, WalkMe, Autodesk, and Sunrun☀️ and partnered on content with companies like Nvidia, Bright Data, & HP.
I've also mentored at bootcamps (Springboard & Data Science Dream Job) & spoken at a number of conferences & career panels (Lesbians Who Tech 🏳️🌈, General Assembly, etc) on breaking into data science & machine learning.
In my free time I love doing CrossFit 🏋🏻, designing & making clothes & shoes 👟, boxing 🥊 , and spending time with my family & friends. Newest hobby also includes amateur birding. 🦅 🔭
Tl:dr 💁️ ➡️ 👩🔬;
How I went from hair salon girl to data scientist working for an innovative digital health company with no Master’s, PhD, or background in a quantitative college degree.
“Work is love made visible.” — Kahlil Gibran
“The written word is all that stands between memory and oblivion. Without books as our anchors, we are cast adrift, neither teaching nor learning.
They are windows on the past, mirrors on the present, and prisms reflecting all possible futures. Books are lighthouse erected in the dark sea of time.” — Disney’s Gargoyles, Season 2
My goals are to provide a comprehensive overview of my data science journey, answer common questions about becoming a data scientist, and encourage aspiring data scientists of all backgrounds.
I am incredibly happy and passionate about working in data science. Title of data scientist aside, I feel incredibly fortunate to work in a field that is constantly innovating, on projects that have immense strategic impact, and with teammates and colleagues that are ‘Wicked Smaht’.
The reality is that there’s a ton of misconceptions about what it takes to become a Data Scientist (along with the existential ‘What IS a data scientist?’). And with every data science & machine learning influencer spouting their opinion of what a “real” data scientist is (unicorn, amazing full-stack engineer capable of whipping out proofs on a whiteboard & regurgitating Cracking the Coding Interview cover to cover)…it’s easy to feel like there’s an ivory wall meant to keep the rest of us non-savants out.
It’s almost as if everyone’s in such a rush to validate their status that the actual requirements are arbitrary.
Data science can be this incredibly interesting, beautiful and creative field that can also seem impossible to break into. I understand how frustrating it can be to read through all these blog posts as an aspiring data scientist and still wonder “Were you technical to begin with?”, “What was your background?”, “How did you fit studying in?”, “What did the rest of your schedule look like?” and even “Does your advice and story even apply to mine?”.
I hope to provide insights gained from my own experience breaking into data science.
In short, my motivating factors for writing this series include:
A desire to contribute my perspective to the numerous diverse stories on becoming a data scientist;
Providing aspiring data scientists with the necessary tools to navigate upskilling and the job search;
Document for easy distribution;
Showing appreciation for the people & places that were instrumental to my career development.
Successful careers are rarely accidental.
More often they start with a spark of inspiration, are pushed forward through a series of fortuitous events with grit & elbow grease, and powered by faith.
The most important factor though is inevitably the kindness of strangers (and not so strangers) who are rooting for you all the way through.
This is my thank you note to everyone who made it possible for me to find a career that I love so much.
Chapter 1: Pre-Data Science
Not Quite Med School Material
“Progress is born of doubt and inquiry.” — Robert G. Ingersoll
“If you’re not prepared to be wrong, you’ll never come up with anything original.” — Ken Robinson

Photo by Ousa Chea on Unsplash
Like many kids of Tiger parents, I’ve had the great honor of disappointing my family twice:
the first time, when I didn’t get into Harvard or Stanford; and
the second time, when I chose to not pursue medicine.
High school could be best described as a “grind”, four years of sleeplessness and burning the midnight oil to keep up with the overachievers. In keeping with the nerd crowd, my high school experience could be quantified by over 13 AP Exams (10 in my senior year alone), 3+ student leadership titles, scholarships for writing and journalism, and a pile of college applications stamped with SAT scores.
I had no aspirations or inclination to pursue data science, machine learning or any of their precursor disciplines in math or computer science, having been told for years that I wasn’t really “that smart of a person”.
After receiving acceptance letters to some great schools that were not Harvard or Stanford (namely Berkeley, Cal Poly, UC San Diego, etc) I chose to enroll in UC San Diego’s biomedical engineering pre-med track. I was determined to go into medicine to help people at scale and then spent the next 4+ years becoming disillusioned as I realized how much of medicine didn’t scale and biomedical engineering was far more research and mechanical engineering focused.

My future class TA — San Diego Zoo. https://www.youtube.com/watch?v=iA7vuUGnrhg
I jumped from major to major and settled on economics and anthropology as my final choices in my 4th year of college. I’d developed a deep love and appreciation for the study of humankind and spent my senior year diving into game theory, behavioral economics, decision-making, evolutionary psychology and public health policy.
Another six years would pass before any of the coursework would be even remotely applicable to my line of work. As I pointed out to one of my Data Science Dream Job students recently (who was saying that their IT-only background precluded them from a career as a data scientist),
The first job I got out of college? Hint, I talk about it in the screenshot below.

Photo by Clem Onojeghuo on Unsplash
You guessed it, it was ‘Unemployed’.
The reality was that when I graduated in 2013 I had no marketable skills, including technical skills like programming (nadda, zilch).
I could do some basic analysis with R from taking one biostatistics classes and some basic statistics classes (as well as multivariate calculus and linear algebra) but only what was required for my major’s prerequisites (and solving the homework problems).
Searching for a job for four months was soul sucking.
Months of no responses lead to depression and I lost 20lbs from not eating (finally! The size 6 pants I always wanted!). I’d run 7 miles a day from my parents’ apartment to the Golden Gate Bridge because I couldn’t stand the failure I saw in the mirror and literally running from my problems seemed the healthiest option. At the end of my run I’d sit by the piers, look out across the fog to the lighthouse ringing forlornly and wonder if my life had been a complete waste.
Did I really have anything to look forward to?

Mom, Dad, Me and Uncle Yasunari at graduation— we’re smiling because we didn’t need to pay tuition anymore and I hadn’t experienced the job market yet.
Against that backdrop, “Data Science”, “Machine Learning”, “Big Data” or even “Advanced Analytics” weren’t terms that were even on my radar. My goal as a newly minted graduate with almost no real marketable skills was just to survive and enter the job market (forget meeting the prerequisites for an entry-level data scientist job).
On the fourth month of Craigslist applying I received an email from a small hair salon owner asking if I would come in for an interview. The pay was below the poverty line in San Francisco and I would struggle.
A job was a job though and I was ecstatic.
At that point many of my friends were well into their first jobs or even working for brand name tech or finance companies. The gap between where I was and where they were would keep coming up in a number of ways, like not being able to afford the same expensive places they liked to go to, not being able to go on trips, feeling the pinch of the drinks bill.
I began to experience intense shame that I wasn’t where everyone around me was in terms of money, professional development, and socializing.
My lifelong mentor and his wife would regularly invite me over to their place with tea and cheer me up. Occasionally Alfred would tell me that one day I would miss this period of my life and that the lessons I learned would be incredibly valuable. The visits and advice kept me sane and going and I’m incredibly lucky to have had their support in that regard for the past 9+ years (as he had also been my fencing coach in high school).
Even though “hair salon girl” isn’t a title most people would brag about their LinkedIn profiles or resumes, I learned some of my most important lessons from opening the shop in the morning and sweeping customers’ hair trimmings. Lessons that included humility (the ability to see the human underneath the job) and ownership (the ability to take pride and pursue excellence regardless of the job).
In between sweeping hair and changing out shampoo bottles I’d talk to our clients (many of whom worked for start-ups) and learn about the new careers starting to pop-up in the tech industry. Over time I started to ask myself, “Why can’t I be working on the kinds of projects they do?”
“What separates me from them?”
After experiencing another verbally abusive client I was determined to go into the tech industry and prove myself.
Seven months later I quit the salon and landed my first role as a sales hacker for an early stage recruitment tech startup. I had no clue what I was doing (and from an experience standpoint, almost nothing to offer other than grit and energy) and they really shouldn’t have hired me, I was so ridiculously unqualified to be successful in that role. At the coffee interview in SOMA’s Sightglass (of course) I asked honestly why they would take a chance on me for the role. My manager Jenn said that I had the right attitude, sounded smart, and showed drive to learn what I didn’t know.
I’d always been a book worm but never considered business or personal development books as anything but “self-help” books.
However, I knew I needed help in my new endeavor from my mentors at a distance and understood that I didn’t have all the fundamental tools for excelling professionally, financially, and emotionally.
During that time I read books that would eventually become incredibly influential for my career, including:
Cal Newport’s “So Good They Can’t Ignore You: Why Skills Trump Passion in the Quest for Work You Love*”*,
Reid Hoffman’s “The Start-Up of You”,
Meg Jay’s “The Defining Decade: Why Your Twenties Matter And How to Make the Most of Them Now”,
and Mihaly Csikszentmihalyi’s “Flow: The Psychology of Optimal Experience”.
My mentors at a distance helped me learn that:
● Career advancement is about the strategic accumulation and leverage of career capital;
● Careers can be directed and should be a combination of taking informed risks (in the form of opportunities) and developing a craftsmanship mindset;
● Much like startups your goal in your career should be to innovate, test, gather feedback and re-adjust;
● Highly desirable careers are characterized by: Autonomy, Competence, and Relatedness;
● Highly desirable careers are attained through high skill & experience (aka you got to work at it — nothing is handed to you);
● People can change & change in outcome comes from a change in actions.
Realizing that I was the only person responsible for MY career and professional fulfillment was freeing.
With this knowledge, I was able to take a step back from the mess of my college career (that was ultimately capped by a generous overall 2.3 GPA) and introspect (as well as reframe my college narrative). The intense shame of my performance in college and my inability to be successfully passionate was unconsciously plaguing me and holding me back from taking purposeful control of my destiny.
In high school, all my motivation for the pre-med route had been external (i.e. get good grades to avoid getting yelled at, sign-up for extra classes to get into an acceptable college so I didn’t get yelled at and embarrass the family, etc).
When I got to college and no longer had the external pressure of parents and report cards, the scaffolding began to fall apart as I had no internal direction or North Star.
As soon as I learned that getting a great career was less like bass fishing and more like building blocks, I began to start planning out and thinking critically about the ROI of my most precious (and only) asset, since I was flat-broke and living with my parents: time.

“No Minute Gone Comes Ever Back Again. Take Heed and See Ye Nothing Do In Vain.” — A random window I saw in London during a business trip. This window and its words haunt my day-to-day.
The first couple months of working at my first start-up RecruitLoop comprised of going out salsa dancing and drinking 3–4 days a week with my start-up friends (really productive stuff, huh?).
One Sunday while getting brunch-time pina coladas, one of my friends bemoaned how she was surrounded by curious and industrious geniuses at Google and couldn’t understand how they also maintained side hustles and personal projects. Her boyfriend responded with “they’re probably not having pina coladas on a Sunday morning” and it hit me that I was wasting valuable time that could be spent improving my mind, body and soul. (That ended pina-colada Sundays for me.)
With help from my bodybuilding friends from the gym, I broke out of the drinking and partying circuit and built up a routine where I’d spend my days working and my nights and weekends taking both online and community college classes in Java, database development and GIS.
Afternoons or nights would be spent working out with my gym buddies.
I’d also learn as much as possible from my leadership and ask them for suggestions on books to read (Mike’s recommendation of The Minto Principle has served me incredibly well, along with Jenn’s growth book recommendations), upskilling resources, and conference tickets.
(Note: I am incredibly grateful to my mentors Jenn Steele, Michael Overell, and Paul Slezak as they helped me learn the guts of sales operations and the recruitment industry during my time at RecruitLoop. Between setting up the lead gen funnel, learning the ins and outs of Salesforce and other key sales enablement tools and sales analytics, I learned so much and they’ve continued to support my career beyond RecruitLoop).
Over the next couple years, I would pivot from being a part of growth ops at RecruitLoop, to performing data analysis and report automation at Digimarc (an anti-piracy company), to strategic FP&A sales modeling at Sunrun (the nation’s leading residential solar company).

The Funnel: A core concept that data scientists should understand i.e. the business funnel. https://trackmaven.com/blog/marketing-funnel-2/
A Non-Lateral Move
“If everyone is thinking alike, then somebody isn’t thinking.” — George S. Patton
“Millions saw the apple fall, but Newton asked ‘Why’.” — Bernard Baruch
By the time I reached Sunrun, I’d managed to come across a number of data scientists and data science meetups. I was captivated by the kinds of complex and challenging problems they were solving (and sometimes creating). I was also beginning to focus away from strategy and toward more data-driven projects.
People ask me: “Was there some stroke of inspiration?” “Was there a show or movie like ‘A Beautiful Mind’?” “ Did I get my hands on a dataset or python tutorial and feel the bite of passion?”
The answer is: Nope.
I’m one of the most risk-averse obsessive-planner types out there.
The pivot to data science was a strategic decision in that:
● I didn’t want a senior role in sales ops/enablement
● I didn’t want to continue in finance
● I had built up marketable skills in data
● I knew that to become a leader in data science (or analytics) I needed to develop a breadth and depth of valuable experience in big data and predictive modeling — and I especially wanted to be a “player-coach” leader, as opposed to a purely administrative manager.
Around that same time, I received a call from my mentor and prior manager Eraj Siddiqui about a potential opportunity.
We had worked together at Digimarc and he had moved on to an innovative company called Autodesk and was hiring for a hybrid data analyst/data scientist role focused on customer success and product adoption.
After receiving an offer I threw myself into the work and projects.
I learned so much about product adoption, analyzing feature usage, segmenting users, tracking customer success KPI’s and preparing for QBRs and am incredibly grateful to Eraj Siddiqui, Jeremy Robson, and the BIM Adoption team for the growth experience.
By this point in my career, I had accumulated domain experience working with every core business partner possible (finance, sales, marketing, customer success), developing both a deep and wide understanding of key business metrics & reporting tasks, as well as an understanding of the “funnel”.
I’ve also experienced working with great companies in a variety of industries like solar, anti-piracy, recruitment tech, and modeling software. I now had some skills in SQL and R (including creating an automated scoring system that would load & summarize usage data, apply rules-based logic to determine the trend of usage, load labels into Salesforce via API and R packages, and then send email notifications to adoption reps summarizing the accounts needing follow-up).
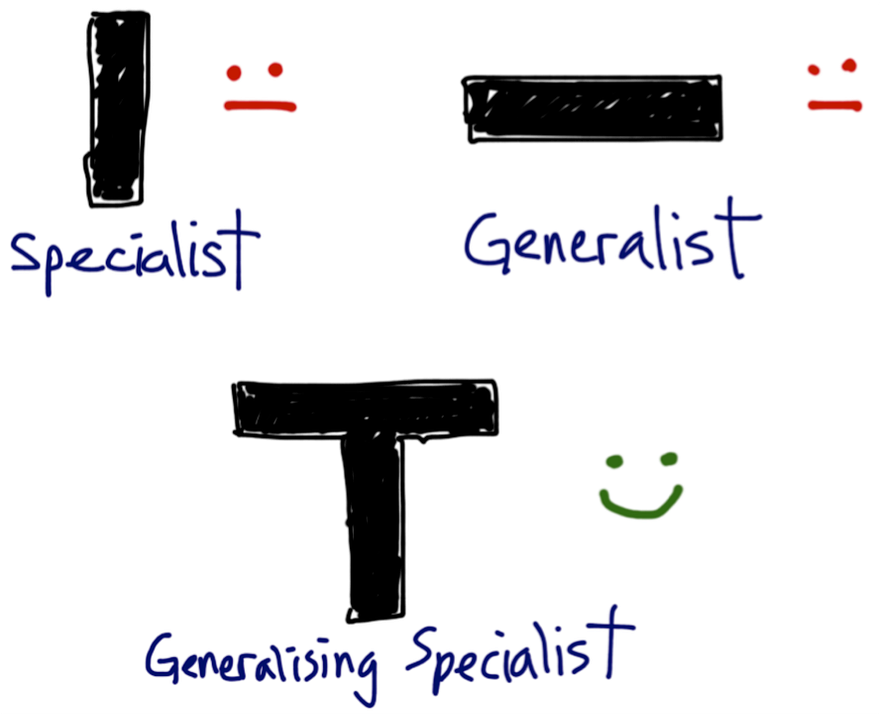
I was more of a squished W-shape at this point. https://en.wikipedia.org/wiki/T-shaped_skills
However when I started working on more complicated questions like “Predicting user churn”, “Automated segmentation & analysis (aka clustering)”, and “Predictive health scoring” I began to struggle as the very junior “data scientist on an island”, including accessing, processing and visualizing big data for machine learning.
I realized I didn’t have quite the tools, skills or resources to learn and develop into the kind of data scientist I wanted to be and this would become very evident.
Chapter 2: The Uphill Climb to Upskill

Photo by KAL VISUALS on Unsplash
The Big “No”
The mind that opens to a new idea never returns to its original size. — Albert Einstein
Research is formalized curiosity. It is poking and prying with a purpose. — Zora Neale Hurston
After about 6 months I had the chance to interview for an internal data scientist role on a different team and completely bombed the interview (I know, so brave for admitting failure right?). During the post-interview debrief I asked one of the senior data scientists what I could have done better. “Could I have displayed a better attitude?” “Could I have studied more on specific topics?”
After silently looking at me for a few minutes, she said:
“With the state of the data and data infrastructure such a mess here, you really need to be at a senior level to do well … at times it’s hard even for me to manage the different work streams across shifting priorities, teams and projects”.
She encouraged me to try to find a place where I could work on data science-y projects end-to-end, get more hands-on experience and have the time to also attend a boot camp or academic program on the side. I needed some kind of formal learning structure and environment as hacking the process wasn’t working out.
A couple of months after our discussion I made the strategic decision to transition to a company that had a single central data warehouse, a significantly smaller product portfolio and a smaller data team.
I took a title cut and moved to a role where I’d be able to build out my portfolio and have total autonomy over my projects (including end-to-end model building, from project scope to feature engineering to model evaluation and deployment).
There were people in my network that couldn’t understand why I would leave an established company (with a great benefits package & salary) for a lesser known early-stage start-up.
Even my family, friends and closest co-workers asked me what I was thinking (correction, whether I was thinking).
“Isn’t a start-up risky?”
“How do you know you picked the right one?”
“What if you regret the move?”
“You just got through the hard part of the first year, why would you just go and leave your budding network?”
Thankfully though, I had experience working for start-ups earlier in my career, which helped me understand that risk is relative and that I could survive the boom-bust cycles of start-up land.
Given the informed risk I was taking, the answer to me was pretty clear: I needed to keep pushing forward. I needed to get my hands dirty with valuable projects, working with data and building models. Most importantly I needed to make a conscious decision to invest very deeply into upskilling in a structured environment and commit to the journey.
Evaluating my options & Choosing a boot camp
A system of education is not one thing, nor does it have a single definite object, nor is it a mere matter of schools. Education is that whole system of human training within and without the school house walls, which molds and develops men. — W. E. B. Du Bois

In putting together my criteria for a data science program I needed to consider the following:
Length of program: Keeping the momentum up would be key to continual progress, so preferably =< 6 months.
Academic (Master’s) vs Bootcamp: This was an easy one as basically all the grad schools I called said “no” (apparently no one’s in a rush to enroll a dunce cap-wearing, 2.3GPA wielding troglodyte). So boot camp it was.
Full-time or Part-Time: The opportunity cost of a full-time program, aside from the cost of the program, included missing out on earned income + gaining experience in that time. (San Francisco rent is also insane)
Cost & Payment Plan: The cost needed to be less than $10k. Springboard came in at $1.5K per month with the monthly plan which was incredibly affordable, especially on a cash basis.
In-person or Remote: Although I enjoy in-person classes, traffic & commuting in SF are nightmarish. Remote also meant I could structure my study around my work hours.
Program Structure: Essentially I identified 3 key components as being important to me: mentorship, project development, and career assistance. The program needed to meet these key criteria (but not much else).
To summarize: At less than $1.5K per month (spread out over 6 months), with a weekly mentor check-in, and decent course material (curated from external sources), Springboard seemed like a great option. I would also have two machine learning projects that I could take to potential recruiters. An additional benefit was that as part of the program Springboard partners with DataCamp to give you access for 6 months after the program ends.
Overall Springboard proved to be a great investment and has entirely changed my outlook on the value of non-academic boot camps or certification programs.
Springboard’s program focused on python and I went from having never, ever, ever touched python to learning how to leverage core data science libraries like numpy/pandas/sklearn/seaborn/seaborn, being able to roughly describe various tasks & concepts in machine learning and build some decent classical machine learning models.
My Personal Apprenticeship

A map does not just chart, it unlocks and formulates meaning; it forms bridges between here and there, between disparate ideas that we did not know were previously connected. — Reif Larsen
As part of my personal apprenticeship, I focused as much as possible on using the tools and skills I learned in the curriculum to initiate and execute data science projects at my company for the real-time hands-on apprenticeship-like experience.
For example, for my ‘Sales Classification’ model, I needed to access our redshift instance using SQL Alchemy, meet with our data engineer to track down data and confirm sources, talk to our Salesforce team to understand if additional data could be pulled upstream from our SFDC instance and talk to sales ops to understand potential opportunities for further data enrichment through external data apps. Once I completed a first pass of the model I also needed to socialize the findings with my core business partner team, present the model performance and methodology to the BI team, and utilize model interpretability (in the form of partial dependence plots) to speak through the feature importance and impact on predicted labels with VP of Marketing.
I would work on the model during lunch or after everyone had left the office, review the progress with Rajiv Shah at the end of the week, read through various tutorials and sites to solve problems as they came up, and then update my business partners on any interesting findings.
My mentor Rajiv Shah would give me valuable feedback on my capstone projects as well as on how to interface with key stakeholders, point me in the right direction when I needed additional learning resources, and would cheer me up when the impostor syndrome would rear its ugly head up.

How my week typically looked. My weeks were booked weeks in advance, no room for anything or anyone that wasn’t working, working out, studying, family or date night time.
By the numbers:
Hours spent on the boot camp (studying/working on assignments/projects) per week: 5~15 hours (could be as much as 20 hours when debugging and refactoring).
Duration of bootcamp: 8 months (initially slated for six months).
Artifacts produced: Two capstones and at least six mini-projects.
Other activities during this time: Working full-time (M-F, 40 hrs per week), training at the gym (4–5 days X week at 3 hrs per session), weekly family dinner (Saturday nights), date nights with boyfriend (two nights per week + one brunch). Occasional movie nights with my boyfriend and/or friends or work trips. There wasn't room for anyone or anything else during this time including close friends.
Study times: Study would occur around lunchtime (12p-1:30p), and end of the day (4p-5:30p) with some more study occurring at night after the gym between (9p-11p). Work happened around those times.
Materials Consumed: As part of the Springboard curriculum I also completed about 22 DataCamp courses, watched at least 30 hours of videos (probably a lot more), and read at least 100 pages of articles directly recommended or necessary for solving the assignments.
Final Thoughts on my Boot Camp Experience
I thank whatever gods may be
For my unconquerable soul.
I am the master of my fate:
I am the captain of my soul.
— “Invictus”
Although the program was estimated to take six months, I needed to take another two months to complete all the projects.
However, I’m proud of myself for taking on the challenge, doing the best I could, and always trying to push the envelope with my learning.
Prior to Springboard I struggled to complete MOOCs and online courses or programs.
Not only did I finish but while I was working on the boot camp nights and weekends, I was also spending meaningful time with my family and boyfriend, taking care of my body, working full-time, and learning to cook (along with doing extra readings and study related to data science).
At any point in time, I could have given up. Instead, I dug deep, rearranged my schedule, stayed up late, work up early and disciplined myself to make time to complete the assignments.
Areas that I particularly grew in as a result of the program:
Applied statistics & probability theory: Traditional statistics had been my weakest area so what I needed to do was cover half my bedroom with whiteboard wallpaper, take my notes and rework them until I understood the logical structure in the context of solving product and marketing problems.
Learning to stay focused: I had a really bad habit of rat holing when it came to feature engineering or EDA. At some point you have to draw a line in the sand and say “enough is enough”. You’re there to solve problems using data science and machine learning, not to tinker.
Understanding NLP: My biggest struggle was understanding the different algorithms and tasks in NLP. I have no background in linguistics, programming or symbolic languages so I needed to read and re-read every sort of explanation and code example out there.
If you’re interested, you can find out more about my capstone projects here:
Classifying Sales Calls: Github Repo
Classifying Kickstarter Campaigns Utilizing NLP Feature Engineering Techniques: Github Repo
Projects are the top two pinned.
I’ve also documented my Springboard experience and coursework in a single repo as well:
- Springboard Data Science Career Track: Github Repo
Resources that I used to upskill, aside from Springboard’s Data Science Career Track, included:
DataCamp: They offer a number of tracks (which are curated collections of their courses)
Kaggle Learn: Kaggle now offers some notebook based courses on everything from Feature Engineering to Model Interpretability
PyCon Youtube Channels: PyCon 2019 and PyCon 2018
Additional resources are documented in the wiki for my Springboard repo (which is a WIP).
If you’re interested in checking out Springboard (and getting $500 off your tuition), feel free to click through to my referral code.
By the end of the program I had grown my skill set, built out a portfolio with two projects, gained confidence and utilized what I learned to implement projects at work.
The next big challenge was to throw my hat in the ring and navigate the job market.
Chapter 3: The Hunt Begins

Photo by Marten Newhall on Unsplash
The brick walls are there for a reason. The brick walls are not there to keep us out. The brick walls are there to give us a chance to show how badly we want something. Because the brick walls are there to stop the people who don’t want it badly enough. They’re there to stop the other people. — Randy Pausch, The Last Lecture
Success is stumbling from failure to failure with no loss of enthusiasm– Winston Churchill
Who Are You and What Do You Want
When I think back to my job search, the work I undertook to get to my offer consisted of three stages:
(1) Defining my identity and crafting my story;
(2) Resolving knowledge and candidacy gaps; and
(3) Embracing the job hunt grind (including the ups and downs).
The most important factor in determining the success of a candidate’s job search is grit.
When I completed the Springboard Data Science bootcamp I was still experiencing doubt and internally I felt like a fraud (still do, working on it).
I was anxious whether I was “good enough” and I was constantly on edge about whether connecting and helping others would “take opportunities from me”, whether I could “compete and win”.
Anxiety about how I was perceived, insecurity about the lack of letters next to my name.
The constant comparisons were exhausting.
I didn’t feel confident in interviews and even though my resume would get great feedback (along with the two projects in my portfolio) I knew I needed some assistance in crafting a cohesive narrative of my professional and personal experience. I also needed some encouragement from data scientists that had fought the good fight (and won).
Months before starting Springboard I had stumbled across Kyle McKiou’s Data Science Dream Job mentoring program. I was hesitant about the potential ROI. But decided to connect with Kyle on LinkedIn anyway so I could follow his content and LinkedIn posts. At some point during Springboard I also signed up for one of Kyle’s webinars to get access to the Portfolio mini-course and was impressed with his down-to-earth explanations and easily digestible format.
After completing Springboard and feeling stressed about the impending job search it felt like the right time to sign up for the DSDJ program.
Stage 1: Defining My Identity and Crafting My Story

Photo by Nadine Shaabana on Unsplash
If you know the enemy and know yourself, you need not fear the result of a hundred battles. If you know yourself but not the enemy, for every victory gained you will also suffer a defeat. If you know neither the enemy nor yourself, you will succumb in every battle.― Sun Tzu, The Art of War
In the fields of observation chance favours only the prepared mind. — Louis Pasteur
Mental Mastery is introduced early in the DSDJ website’s curriculum because of the central importance of grit, capability and positive psychology to anyone’s success, whether personal or professional.
Some key resources that were recommended early included Angela Duckworth’s Grit, readings from Carol Dweck, and other leaders in positive psychology like Anders Ericcson.
Through a combination of Kyle’s talks, reading recommendations and module exercises included in the program, I began to notice significant shifts in my mindset.
Some of the most significant changes included:
Being able to recognize constructive feedback as a sign that someone cares about where you’re headed and is trying to suggest ways to get you there faster and more effectively. Not a personal judgement or labeling of your worth.
Being comfortable with failure and reframing failure as learning. In the course of challenging and pushing beyond your existing boundaries, you’re going to take some risks and some of them won’t pay off. And that’s okay. Rather than laying on the ground you pick yourself back up and adjust.
Being able to see that my personal and professional experiences are additives to the right team, at the right company, at the right time. Just because my background was unconventional from an education and early professional experience standpoint didn’t mean it wasn’t valuables.
Being able to accept that I didn’t “deserve” an amazing, creative and financially rewarding career, or at least anymore than anyone else around me. No one inherently “deserves” the best career nor is anyone inherently “undeserving”. Instead people “earn” their best lives through their choices and decisions every day. And this is a particularly tricky concept because rather than saying, “No one deserves to be happy”, my interpretation is closer to “you get what you put in”.
After reprogramming my mindset, the next step was crafting my story and positioning my unique value proposition to employers.
A lesson I learned early on from working at my first startup (which was focused on recruitment tech) was from a manager, who quite succinctly summarized what many recruiters and hiring managers are probably thinking: “No cares about your ASPIRATIONS”. Hard lesson to swallow but true. Another version is “It’s not about what the job brings you but what you bring to the job.”
At the beginning of a data science job search, the temptation is to try to fit everyone’s definition of a data scientist and boil the ocean.
While keyword-matching your skills and experiences to job postings is important, as well as building really cool projects for future “You”’s portfolio, even more important is owning the pieces of who you are NOW and incorporating those pieces in your narrative.
There’s a fabulous chapter in Meg Jay’s book “The Defining Decade: Why the 30’s are not the new 20’s” that includes a vignette where she’s gnashing her teeth trying to get her counseling client to commit to a career. He works as a mechanic in a bike shop and is unsatisfied with his current role but won’t commit to an alternative career because every other career out there feels off the shelf and not extraordinary. Jay is finally able to reach him when she compares his custom bike to a career; a unique amalgamation consisting of off-the-wall parts built up over time.
Another way to think about the value of a unique story is considering the perspective of a recruiter or hiring manager.
When you have 20–30 resumes gliding across your desk, it’s easy for candidates to start blending in a pool of words and formatting.
Degrees, certifications, skills, recommendations.
Do they become just another bullet point on your resume or do they become a supporting point in the arc of your narrative?
And professing yourself as “passionate about data science”, “interested in” or “pursuing data science” isn’t enough either for your elevator pitch.
Hypothetically, everyone looking towards a career in data science is passionate about…data science. Your story needs to be far more unique and relevant and it needs to come from owning the experiences and skills you’ve already developed that can additional value.
Another way to think about your unique value proposition is thinking about your “superpower”. A “superpower” in this case is any skill that you feel is your competitive advantage. It can be technical but it doesn’t have to be. For all my job searches, the superpower I advertised was my expertise leveraging analysis in various business domains like product analytics, sales analytics, marketing analytics and growth. Specifically my ability to serve as a “data translator” (see these articles from McKinsey and Forbes) was my unique value proposition.
Once I owned my story, non-traditional by most standards for a data scientist, I utilized various DSDJ resources to put pen to paper and populate my resume and linkedin.
Stage 2: Resolving knowledge gaps

Photo by Green Chameleon on Unsplash
Everything you want is on the other side of fear.–- Jack Canfield
Real education enhances the dignity of a human being and increases his or her respect. If only the real sense of education could be realized by each individual and carried forward in every fields of human activity, the world will be so much a better place to live in. — A. P. J. Abdul Kalam
When all is said and done, however, I still needed to systematically resolve remaining gaps in my knowledge and skills.
The two strategies I used were:
(1) Creating a study plan around my weak areas and
(2) Taking on side projects for friends needing data science expertise.
Strategy 1: Creating a Study Plan
After taking a month to relax and catch-up with friends and family, I started writing up a study plan to structure my next 6–9 months of job applying and interviewing. The first draft involved taking every month to focus on the following topics:
Data Cleaning + EDA (Visual Analysis)
Statistics/Probability Theory/Experimentation
Machine Learning 101
Specialized Topics in ML
Software Engineering Best Practices
Specialized Topics in Math
I would use a combination of passive studying resources (videos, podcasts), mid-active studying (technical books, code review), and active studying (coding tutorials, online mini-courses) to focus on artifact creation (projects, code, notebooks, blog posts) as well as reworking my previous projects.
A very rough version of the gantt-like style timeline I had originally adopted for myself during the first pass of creating my study plan.
However like all best laid plans I had to be a bit more agile and change my focus throughout the job search.
Initially I had this really complicated learning plan that focused on stats for two months, then coding for two months etc. But the feedback I got in some of the early interviews was I needed more experience running and calculating A/B/n tests. After squeezing myself into some A/B/n testing projects at work and developing my understanding of experimentation and analysis, I would go into interviews and do well on the stats questions and then die on algorithms questions.
Rinse and repeat.
My take-away from the experience of creating a study plan and then going through a rotating cycle of rejections was that I needed to iterate through the different topics in a much shorter cycle.
The entire data science interview process at some point begins to feel like a fast paced version of whack-a-mole.
Different companies have different needs at different times and no single program or resource will adequately cover all the skills needed for the job.
Strategies and resources I used during this period include:
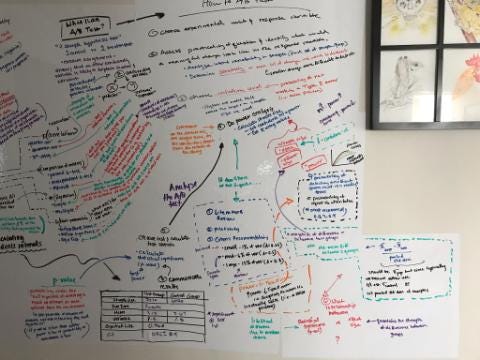
This covers 1/3 of my bedroom wall. I later added another two sections of stick-on whiteboard paper.
Practicing on whiteboard wallpaper that I stuck all over my apartment
Taking architecture grid notebooks and writing out example code blocks & notes while going through coding tutorials
Practicing SQL and Python questions on HackerRank, LeetCode, and CodeWars
Completing at least 1–2 DataCamp courses a week and utilizing relevant code snippets in personal projects or posting to team wiki
Watching PyCon videos when possibleStrategy 2: Taking on Side Projects and Learning to Think Like a Business/Product Owner
Purchasing used O’Reilly books (Practical Statistics for Data Scientists: 50 Essential Concepts by Bruce, Data Science from Scratch: First Principles with Python by Grus, Python for Data Analysis: Data Wrangling with Pandas, NumPy, and IPython by McKinney, Hands-On Machine Learning with Scikit-Learn and TensorFlow: Concepts, Tools, and Techniques to Build Intelligent Systems by Géron) and reading through them multiple-times on the commute, then going home and practicing the queries using Colab or Jupyter notebooks.
Strategy 2: Side Projects
During this period I also started helping out with side projects, from fitness to real-estate. My family didn’t understand why I would do “free work” after paying for a boot camp.
While I can’t say much about my friend’s projects right now, I can talk about the rationale behind why someone might want to consider contributing to other people’s projects, even if they’re not open-source.
The main reason why I spent some nights and weekends working on other people’s projects is the ability to get hands-on experience in areas like:
(1) Creating production quality code;
(2) Formulating prediction problems from scratch using challenging and disparate data;
(3) Model deployment;
(4) Feature engineering in a production-like setting.
The kind of experience and upskilling that comes from being an individual (and sole) contributor at an early stage start-up is a different experience from being part of a team on a mid- or late-stage company.
I initially just saw it as an opportunity to gain valuable experience and work with smart and interesting people while continuing my main job search for a data scientist role.
What happened was the minute I took co-ownership of the product, everything I‘d learned about product analytics, data science, and growth marketing started to click into place.
Suddenly the seemingly endless and opaque list of requirements for data scientists (like experience with proper statistical testing and experimental design, agile model deployment, good testing and debugging, end-to-end visibility of the product) started making sense, especially in the context of being a data science product owner.
Even if you’re not working on a side hustle, you can learn to adopt the same mindset by imagining that you’ve just been hired for a job as the sol data scientist for a start-up.
When you’re creating your own consumer machine learning product that needs to successfully ship and meet customer demand such that significant market share is captured in a short period of time, all your inputs and decisions matter, especially given you’re trying to pay yourself in the future.
After working on side projects I determined that for my next role I wanted to become the kind of data scientist that is:
(1) Creating internal data products that power customer-facing apps;
(2) Performing experimentation, segmentation and causal inference analysis;
(3) Incorporating machine learning into strategy, forecasting, and planning;
(4) Constantly learning & pushing the boundaries of my knowledge & experience with advanced machine learning topics, like reinforcement learning, deep learning, computer vision, autonomous vehicles
Stage 3: Embracing the Highs and Lows of the Job Search
Never stop fighting until you arrive at your destined place — that is, the unique you. Have an aim in life, continuously acquire knowledge, work hard, and have perseverance to realize the great life. — A. P. J. Abdul Kalam
I must not fear.
Fear is the mind-killer.
Fear is the little-death that brings total obliteration.
I will face my fear.
I will permit it to pass over me and through me.
And when it has gone past I will turn the inner eye to see its path.
Where the fear has gone there will be nothing.
Only I will remain. — Bene Gesserit, Frank Herbert

Photo by Simon Watkinson on Unsplash
Putting in the Emotional Work
Sometimes the hardest part of the job search, whether data science or not, is the emotional work. It’s easy to point to all the reasons why you can’t succeed or won’t succeed. But what if the problem isn’t the skills, experience, background…what if the problem is YOU?
What if the problem wasn’t with all the things you couldn’t control but all the things you could?
It can be an incredibly uncomfortable experience looking in the mirror and being honest with our shortcomings.
In my case there was security in not taking accountability and ownership of my success. There was security in saying “One day” and then trying to control the job hunt situation by planning, planning and more planning. Planning and never doing.
During an office hour call with one of the DSDJ mentors (who I’m now happy to call a colleague), I showed off my elaborate study plan and talked about how I was going to target applying for jobs “6–9 months in the future”. I promptly got my hand (digitally) slapped and was challenged on the timeline. “Why WOULDN’T you try apply now to at least five jobs?”. The question was fair and Harpreet encouraged me to suck it up, do the work, and apply to at least five jobs on LinkedIn. Worst case scenario I get rejected, adjust my resume and study based on the original timeline.
Committing to achieving the outcome
After a month of LinkedIn applying I started getting some bites from recruiters for data scientist roles heavily focused around decision science.
Regardless of advice I’ve seen to tailor portfolios around specific data sets and problems in specific industries, I received call backs from every type of company in every type of industry possible.
At some point every company needs to sell and my background working with sales and product analytics meant I had a valuable skill set that wasn’t industry specific.
Of the 5–15 applications I sent out every day, I’d get positive responses from 15–20% of the roles (the remainder being auto generated rejections).
Over the month I would go through a very similar process of: recruiter call, team member screen, technical screen via CoderPad, hiring manager call, take home study, onsite interview of 4–12 interviewers (with some rounds being whiteboarding sessions and others being walk-throughs of projects I did, along with behavioral questions).
Whenever I didn’t make it to the next round I’d try to get as much feedback as possible and incorporate the feedback into changes in my study plan.
After the second month of purely focusing on interviews I realized I needed more time in my schedule to productively break from the constant grind and work on interesting data science problems, even if they were just personal projects or snippets.
After a skype session with one of my best friends Veena where she talked about getting up at ~ 3:30–4 am to compose music for two hours before going into work as an engineering manager, I was inspired to do something similar.
My new schedule consisted of:
Waking up 2–2.5 hours earlier every morning (~ 5:30–6:00 am) to code and study for two hours;
Heading into work around 8am and using the commute to read or watch data science related videos;
Use lunch time/midday to do more coding and read through tutorials between 12pm — 1:30pm;
Leave work around 4:30pm to get to the gym or the boxing club for 2–3 hours of training;
After heading home for dinner and a shower, turning off all electronics at 9pm ;
Blocking off the last 1–2 hours of the night to improve my sleep hygiene and relax.
I was still using weekends to work on side projects with friends and take of chores, as well as spend time with family.
By front loading the most important tasks in the morning when no one was awake and I had the most energy, my mood improved drastically and I was able to produce more work.

Still no social life but I have no regrets as it was the most fulfilled I felt the entire job search.
By the end of month three I was getting into a cadence of study, apply, interview, more apply and more interview. But the offer I wanted always seemed just out of reach and I was losing a little bit of steam.
Was it all a waste? Was all the effort worth it? Did I make a mistake? Or several, kind of expensive mistakes?
Chapter 4: Landing the Data Science offer
Young men, have confidence in those powerful and safe methods, of which we do not yet know all the secrets. And, whatever your career may be, do not let yourselves become tainted by a deprecating and barren scepticism, do not let yourselves be discouraged by the sadness of certain hours which pass over nations. Live in the serene peace of laboratories and libraries. Say to yourselves first : “What have I done for my instruction?” and, as you gradually advance, “What have I done for my country?” until the time comes when you may have the immense happiness of thinking that you have contributed in some way to the progress and to the good of humanity. But, whether our efforts are or not favoured by life, let us be able to say, when we come near the great goal, “I have done what I could.” — The Life of Pasteur (1911), Volume II, p. 228

Photo by Gabrielle Henderson on Unsplash
My interview for the Data Scientist II role in Growth Marketing at Livongo was fairly typical in structure.
The interviews were as follows:
Recruiter Phone Screen
Hiring Manager Phone Screen
Take-Home Case Study (involved creating a simple model)
Onsite with two members from the Growth Marketing team, a senior member of the DS growth team, DS hiring manager, & a whiteboarding/SQL questionnaire from another senior member of the DS Growth team. Each of the interviews were 1:1.
Follow-up phone call with DS Hiring Manager to brush up remaining questions.
I had a few other interviews in the queue including final rounds. When the verbal offer came in from Livongo, the role seemed to be the right fit at the right time. Mission-driven company, big data science org (at least bigger than the analytics/business teams I’d worked on), and a data science offering that was still evolving.
I accepted the offer approximately at the end of September, four months after completing Springboard in June 2019 and 2–3 months after starting Data Science Dream Job.
After accepting the offer for DS II at Livongo, I went on to also mentor at Springboard for a few months and Data Science Dream Job for about seven months.
It was a hectic period full of learning and productive growth. I was mentoring at two data science/analytics programs, working as a data scientist full-time, consulting part-time (while maintaining a 20 hr week gym schedule). I got to participate in datathons, speak at conferences for organizations like Lesbians Who Tech. I was helping to answer and help tons of students and aspiring data scientists via LinkedIn (enough that I started copy-pasting responses).
Hosted a workshop/talk at Lesbians Who Tech’s Not IRL Summit

We got in the top 10 teams for our Social Distancing Index analysis.

Was chosen for GHC 2020 Scholarship, sponsored by Amazon
Chapter 5: Be Careful What You Wish For…
And from the moment that I saw you, I knew you was trouble,
But I disregarded detour signs,
And did not stop til you was mine.
I guess God was like, ‘Aight, fine.’
Careful what you wish for, cause you just might get it in heaps.
Try to give it back, He be like, ‘Nah, that’s yours to keep.’ — Mos Def
Although I was doing everything I thought a “real” data scientist should be doing, I was also starting to burn out. I realized I was at the end of my rope when I began to get angry and feel tired all the time doing really simple tasks.
I’d get another message on LinkedIn for help, another request for speaking, staying up later to answer messages on LinkedIn & getting headaches from the lack of sleep.
Even after dialing back on a few activities and being more strict about maintaining boundaries, especially online, I realized that I still loved parts of what I worked on but not everything. I needed to become more selective about the areas of data science and machine learning that really interested me and were worth putting in energy (and will no doubt continue to interest me for years to come).
Then COVID and quarantine hit and a lot of plans went belly-up and it’s been a struggle since to get back up and push through on some of the same goals. I realized that at the end of the day, if you’re not doing the kind of work you want to be doing, it’s not always enough to change your perspective and mindset. Grinding it out & hoping for the best isn’t always the right answer. Sometimes, as Seth Godin points out in The Dip, you’re in a Cul-de-Sac (a dead-end) as opposed to a Dip (a temporary setback that you can push through).
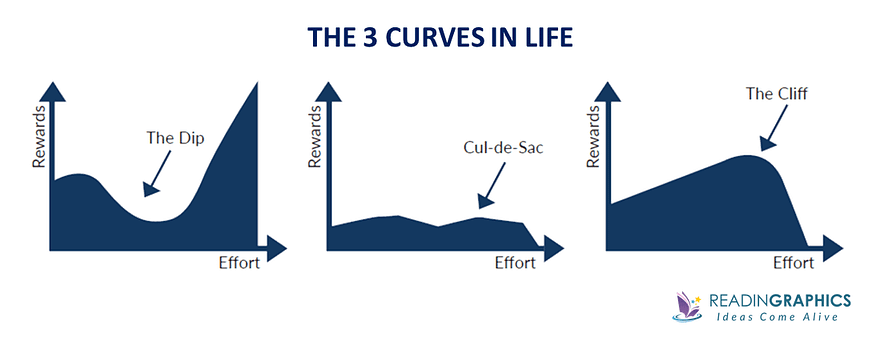
One of these is not like the others.
My time in quarantine made me realize that if I didn’t start making moves on the projects I care about and taking risks, my future self and goals would eventually be left behind.
I took the big step last month to pass on my best wishes to my peers at Livongo in their new phase as members of Teladoc without me, as I work on a new venture in real estate tech.
My goal is also to take personal time to focus on growing and developing my skills in key areas of machine learning and AI. A personal AI Fellowship if you will, in the vein of the OpenAI fellowship (whose rejection partially inspired me to come up with my own deep learning & computer vision learning sabbatical — thanks y’alls!).
All this goes to show that life comes at you fast and as the saying goes, “Man Plans, and God Laughs.”
Chapter 6: My Key Takeaways on Breaking into Data Science (What I did right & What I would do differently)
“Great people do things before they’re ready. They do things before they know they can do it. Doing what you’re afraid of, getting out of your comfort zone, taking risks like that- that’s what life is. You might be really good. You might find out something about yourself that’s really special and if you’re not good, who cares? You tried something. Now you know something about yourself” — Amy Poehler

Nonetheless I’m proud of myself for having broken through that first major milestone (getting a data scientist job) and if I were to go through the process again (say a year from now), here are the things I would do differently (or not).
The 5 Things I Did Right
1. Getting started exploring early
It’s really easy for time to just creep up, especially when you don’t have a clear goal in mind. Some would even say time seems to speed up as we get older. One reason why time can seem blurry is because once we get past college (or grad school), there are far fewer transformational achievements and external pressure (and when there is external pressure, it’s to conform). And when you combine key milestones being pushed back further, with many people taking up to 20–30 years to hit their peak potential, there’s a good chance that delaying your exploration means you won’t see real gains from switching to data science in your working lifetime.
All of this is to say, do the math.
If it takes a year of study, applying & interviewing, then an addition 2–3 years to get to a senior level, it’ll be at least three years from the time you commit.
Get started earlier so you can reap the benefits earlier.
2. De-risking as much as possible, when possible (& leverage Tripod of Stability)
Students & mentees have asked me whether they should quit their current jobs to study or do bootcamps, whether they should turn down jobs that aren’t a fit while interviewing for other reach roles. Most of these “burn your boat” questions depend on your individual risk tolerance and ability to recover from the consequences.
In my particular situation I was blessed with some safety nets that included a below-market rent controlled apartment (thanks SF!), a partner that had a full-time job (and rent controlled apartment) that was supportive of my career, living in the same city as my parents (who would never let me go homeless), and an emergency account I had built up through aggressive saving over the prior years. My students loans were also fully paid off, car was mostly paid off and the remaining monthly payments were incredibly low. Between all these safety nets I could have quit my job.
But I didn’t because I have a deep seated fear of debt, being homeless, and not having money when I need it. I was willing to trade time in exchange for keeping money and liquidity. One of my life meta-goals is to always keep my options open and to even build-in options where possible (for example, learning a new skill).
Ramit Sethi advocates for a form of risk-mitigation called the “Tripod of Stability”.
The idea is to keep “three of the most important aspects of your life perpetually stable. This stability gives you the confidence to take the occasional risk.”
In my case, my tripod of stability was my job/income, my core relationships (partner and family), and my routine (work outs, date nights, & family dinner nights). If I decided to quit my job I would have been incredibly stressed out and felt pressure, potentially risking exposing myself financially (no income, drawing down on my savings to pay program) and breaking continuity in my resume.
In general I wouldn’t recommend quitting your job in order to pursue a graduate degree, certificate, or bootcamp (especially if you need to take out a loan). Nowadays most bootcamps have an ISA (income sharing agreement) where they garnish a % of your income once you’ve gotten a job in data science (up to the cost of the tuition plus interest). Typically these ISA’s are a much better option than a loan from the same bootcamp in most cases and a better deal than loans for Master’s programs. ISA’s put the onus on the camp to provide career assistance in the form of resume reviews, practice interviews and referrals to prior alumni.
Instead of quitting your job I’d recommend starting your data science endeavors by taking some online courses (preferably with project based components) that are available asynchronously to determine if you have an initial interest. If you take some courses and hate it, then all you’ve lost is a few weeks or months of time and maybe $20–100. Even in that scenario you’re probably learning 1–2 skills that you can utilize in your own work. If you do really like the courses, I’d then recommend getting a hold of a dataset from Kaggle and doing an end-to-end analysis and modeling project (you could even use Kaggle or Google Colab).
3. Being fully informed & doing the research
I’ve gotten questions over the years about whether data science bootcamps (like Springboard) and job search prep programs (like Data Science Dream Job) are worth it. I’ve covered my experiences in both Part 2 of this series as well as different promo pieces for the programs and encourage you to read about my reasons in more detail.
I do want to emphasize that what works for one person might not work for another.
Some factors you might want to consider when choosing a learning medium (and provider) include:
Whether you’re just starting the data science journey or have been at it for a while? (i.e. do you need to cover all your foundational bases or do you just need to deep-dive on specific topics)
Whether you’re someone that needs structure and hand-holding or someone that prefers a more hands-off self-initiated approach? (i.e. do you need a step-by-sep program with clearly defined deliverables or are you okay with a curated list of resources)
Whether you’re someone that needs a consistent, recurring presence or prefers to reach out when you’re stuck? (i.e. do you need a mentor or a support community or both)
Whether your financial situation requires you to continue working full-time or you’re able to take significant time-off? (i.e. does the material need to be asynchronously delivered or can you do live learning)
Whether you have other needs besides learning the skills? (i.e. Are you hoping to have a portfolio or projects?)
Can you get into the program? (i.e. Is there a GPA or prior experience requirement?)
When considering the specific bootcamp (and whether I went the bootcamp route versus getting a degree) I considered and researched all the questions posted above and ended up with the solution that fit me best.
I’d encourage you to also do some research and scenario planning and take everyone’s endorsements with a grain of salt.
Bootcamps can provide a valuable environment for candidates to strategically bridge areas of weakness, create professional relationships & benefit from group learning (but it doesn’t mean they’re right for everyone).
4. Do whatever it takes to succeed
One of my favorite books in the world is “So Good They Can’t Ignore You” by Cal Newport. I first picked up his book in 2013 as part of a personal mission to climb out of the hair salon and into tech and I’ve re-read it many times over the years. A fantastic summary of the book’s central points can be found here but the most salient theme is about how experts leverage a “craftsman mindset” and work on building “career capital” by deliberately and intentionally developing and growing “rare and valuable skills”.
At the start of the Springboard Data Science program I was struggling with timelines and getting work done. I felt like I was putting in hours here and there and squeezing in as much time as possible and still unable to make real progress.
One night I caught up with my friend Veena, who is equally (if not more) growth oriented and a Renaissance woman that works as an engineering director in the day and spends nights singing and playing (as well as composing) music. She is an incredibly multi-talented individual (that also gets business done) and I was really interested in how she was able to be so productive with the same number of hours in a day. I was shocked when I found out that in order to get her creative hours in, she was waking up at 4:30am and going to bed at 8pm (I was struggling to even get up at 9:30 am!).
I realized the answer wasn’t to continue shaving 10–15 mins here and there but to radically redesign my schedule around my goals (or as Cal Newport calls it, creating a “fixed-schedule”) and ruthlessly prioritize everything around those goals. If it didn’t contribute directly to my goals of kicking-ass in the Springboard Data Science track while maintaining my relationship with my family and partners and staying shredded in the gym, it didn’t make the cut. That willingness to make big changes was 8 months of no friends, no parties, no going out, no shopping (to maintain financial liquidity) and being a code monkey.
And guess what? I accomplished my goal and that accomplishment opened so many doors professionally, from getting a main gig as a data scientist, side gigs as a mentor, and speaking engagements and scholarships.
Accomplishing transformational goals isn’t fun and they require you to change as a person. At the end of the day, I’d like to think that we’re aiming to be the people we never thought we could be but had always wished, and sometimes that requires equivalently big changes.
In the words of Mr.Carter,
“People look at you strange saying you changed
Like you worked that hard to stay the same
Like you’re doing all this for a reason
And what happens most of the time.. people change
5. Going all the way
Everyone has probably seen Angela Duckworth’s TED Talk on Grit and her formulas by this point (and if not, it’s worth watching the TED Talk and reading her book). One of her main points is that grit — a combination of passion and perseverance for a singularly important goal — is the hallmark of high achievers in every domain. Another one of her quotes is “Talent counts once, effort counts twice”.

From her book “Grit”
I was never considered a particularly smart individual and certainly not an academic achiever in my early years (writing and journalism scholarships aside). I didn’t go to an Ivy League or graduate as valedictorian. And I wasn’t completing a prestigious graduate program. I could have let these doubts about my ability to get a foot in the door prevent me from succeeding.
What helped me sustain the journey was learning about and developing a growth mindset with the help of mentors-at-a-distance like Carol Dweck . I constantly reminded myself that data science is a collection of skills and skills can be learned. I knew the biggest meaningful differences between myself and other candidates (that might have gotten an earlier start in data science) was time and intention.
So as much as possible, I incorporated learning throughout the entire day.
For example:
I’d spend the first 3 hours of the day going through coding tutorials and videos;
I’d print out notes or powerpoint presentations and study on my bus commute;
I’d use lunch to do more tutorials and coding, as well as the afternoon rush hour (the bonus of hanging out at the office after work ended was healthy snacks and never ending good coffee from Philz);
I’d listen to videos and lectures on the stairmaster at the gym;
Read some more on the bus ride, rounding out about 2–3 hours of commuting.
And then another 2–3 hours of working on projects.
Using the dead time on the bus commutes alone I finished reading “Practical Statistics for Data Scientists” in 1.5 months.
The 5 Things I Would Do Differently
1. Be less picky about the datasets & projects
When you’re starting out and have no projects in your portfolio, it doesn’t make sense to try to find the perfect dataset and the most unique project under the sun.
When you’re first learning about the different algorithms and supervised learning tasks it’s actually better to choose well-documented and bench marked datasets that are publicly available on Kaggle.
There’s a number of reasons for this:
1. Well-documented datasets have tons of sample projects and code that you can compare and contrast;
2. Because others have already worked through the datasets, it also means they’ve done the initial discovery and EDA and discovered some of the major data quality issues (as well as solutions);
3. Modeling is actually the easy part of the data science workflow. Data cleaning, feature engineering, model interpretability and prediction deployment are the hard parts. Working on the easier parts of the process helps build momentum early on in your learning for when you tackle the hard parts.
Instead of trying to find the perfect dataset (or even generating your own through scraping) focus on improving your EDA, modeling, and presentation skills. My Springboard completion got pushed out by two months because I was so busy trying to find interesting datasets and then setting up the ETL’s that I ended up scrambling on the other parts of the projects.
2. Understand the whole data science workflow, instead of rat-holing on specific areas
Personally I despise all the tool talk on LinkedIn. R vs Python, AWS vs GCP, etc. At the end of the day, the majority of us aren’t and will never be in positions where we determine the tech stack for a company. Most of the time you’re adapting to the tech stack that already exists and adding or subtracting personal peripherals (Jupyter, JetBrains, VS Code, who cares, it’s your choice).
So why do we have so many people engaging in battles over tools or point-solutions?
Part of the answer is about the social clout and clicks i.e. there is nothing that gets people more riled up and “engaged” than lambasting another person’s favorite programming language. (And “5 Reasons Why ‘R’ Sucks” is easier to fit in a subject line than the more nuanced and reasonable title “The Trade-Offs and Considerations in Supporting R & R Studio for Non-Academic Analysis in Production Teams”). It’s also easier to copy-paste the features list from the Conda site and rewrite them and add useless commentary than go into the different trade-offs and use cases.
Another part of the reason, I would hazard, is because some practitioners don’t understand enough about how data science and machine learning work in production and oversell the value of machine learning models. At the end of the day if your model isn’t integrated into the business and usable, it’s just another toy project that didn’t bring your business or organization any value. And if you don’t understand the entire workflow (from data to model to prediction to evaluation to serving to monitoring) it makes it harder to figure out what the solution should be for your problem.
When I was working on my NLP project predicting kickstarter campaigns for example, I struggled understanding NLP techniques for feature engineering (tokenization, n-grams, etc) versus NLP tasks (like measuring document similarity, etc). My understanding of the entire modeling pipeline was poor and I ended up spending more time reading up on NLP tasks as opposed to applying NLP techniques for feature engineering and getting creative with the feature engineering and model interpretability (instead I ended up slapping some basic classification algo’s on top of the entire mess).
By now you’ll notice the general theme is that the more you understand about what the process should look like, the less time you’ll spend on the low-value parts of the pipeline.
3. Spend more time on the basics of interviews, as opposed to the fancier, edge-case questions
Because interviews are time-bounded, there’s only so much they can ask you to do (especially now with remote interviewing). I wish I’d spent more time on reviewing the basics (experimentation, EDA, model evaluation & deployment, SQL, leveraging standard python data structures like collections objects) and less on edge-case questions, especially for business data scientist roles. For business data scientists it’s less forgiving if you get a stats or python question wrong than a question about data processing for computer vision models.
If I’d spent more time on going through all the python questions on hackerrank and the python/SQL questions on codewars (and doing the questions on a whiteboard), I probably would’ve had a better chance nailing offers for some of the dream companies out there.
4. Don’t ignore red flags in interviews
If you’re seeing red flags in the interviews about the specific role you’re interviewing for and the team (and the data science maturity of the company), it’s only going to get worse. It could eventually get better but trust that it’s usually a lot worse below the surface.

Illustrative gif.
People who are happy with their jobs and really excited about the company will let you know upfront. When people hiss between their teeth or go “Well, you know, things are always changing” as an answer to a rather direct question, swipe left.

Hopefully a second iceberg gif gets the point across.
5. Marathon, not a sprint
Learning and growing as a master of your craft is a life-long quest and journey. You need to continue developing your skill set and can’t stop just because you get an offer. I regret getting lazy after getting my job and focusing so much on signaling (conferences, speaking, etc) and dropping the “craftsman mindset”.
Notes & References
This mega-post is a combination of posts that I originally published on my Medium account.
You can find them here:



